

Key points
- Building a Site Reliability Engineering (SRE) capability requires changes in hiring, training, and organisation behaviour
- Adopting SRE needs enhanced trust across the IT organisation
- An SRE Managed Service can help organisations get the benefits of SRE quickly and efficiently
In this two-part mini series, we’ll look at the emerging discipline of Site Reliability Engineering (SRE) and how this relates to Managed Services for IT Operations. In Part 1, we covered the basics of SRE, and in Part 2, we’ll look at what SRE means for the IT organisation and Managed Services.
Organisational behaviours and hiring for SRE
The SRE model clearly works well at Google because all the core Google services and applications have had some SRE input to help make them as reliable as they are. But it’s no use just hiring a load of people as “SRE” staff and expecting to get the same kind of reliability as Google has; in fact, just hiring SRE people might be very counterproductive.
To make SRE teams work you will need to hire people with an unusual range of skills:
- Deep knowledge and experience of operating systems, container fabrics, computer networking, alerting, and monitoring
- A drive to collaborate with Development teams on improving the operability of the software applications in Production
- An ability on focus on the business-relevant Service Level Objectives (SLOs), which are typically different for each application or service and set by the Product Manager
These skills are quite far removed from the traditional IT Operations skillset, so you cannot just rename the Ops team the SRE team and expect good results!
As we saw in Part 1, SRE teams have the ability to say “no” to poorly written software changes. This needs a good deal of maturity in the organisation to enable this to happen. In many organisations, if the Development team (or Product Manager / Project Manager) wants to get something deployed, they will pester or push the Production-focused team to deploy the changes even if the software has not been tested properly for Production reliability (some people call this “JDFI deployments”!).
To make SRE work in your organisation, you will need buy-in from senior leadership that the SRE group is empowered to refuse deployments for applications and services that have exceeded their error budget. Also, according to the well-known Google SRE known as JBD, you need to “let your development team own the SRE work if the scale doesn’t require SRE support”. This will feel very different to the traditional approach to IT operations in many organisations, so be sure that you don’t fall short on this.
Enhancing trust for SRE
With an error budget in place, SRE teams can have straightforward discussions with Development teams on how much risk to take on for a particular service or application. In the words of Mark Roth from Google, “[the error budget] metric removes the politics from negotiations between the SREs and the product developers when deciding how much risk to allow”. This means that getting an accurate measurement of service availability is essential for building trust between SRE and Dev teams; in turn, this means you need to invest in high-quality tools and training for SREs to be able to measure and report on service availability in the first place.
Another key practice for building trust is the so-called “blameless post-mortem” as defined by John Allspaw, ex-CTO of operations pioneers Etsy. When something goes wrong in Production (such as an application becoming unavailable), teams work to restore service quickly. After service is restored (and after people have slept if needed) a postmortem (team analysis) of the problem is carried out. The trick here is make sure this analysis is “blameless”, so individuals feel like they can be open with all the details needed and “that they can give this detailed account without fear of punishment or retribution”, as John Allspaw puts it.
Getting the benefits of SRE quickly with SRE Managed Services
According to the well-known DevOps Team Topologies website, the SRE pattern (known as Type 7) is “suitable only for organisations with a high degree of engineering and organisational maturity”. This is because without the trust and engineering maturity to make SRE work well, there is a danger of a “return to Anti-Type A if the SRE/Ops team is told to “JFDI” deploy”. However, if your company doesn’t yet have an SRE function or doesn’t want to build an SRE capability in-house, you can get the benefits of SRE quickly by using an SRE Managed Service.
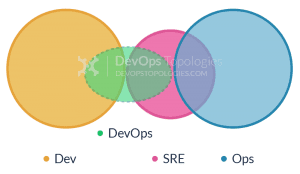
Type 7: SRE Team. Source: DevOps Team Topologies / devopstopologies.com – CC BY-SA
By using an external provider for your SRE capability you get the advantage of a ready-formed SRE capability with all the skills and experience needed to improve the reliability of your key systems together with a clearly defined service contract that sets out SLOs and uptime expectations. The managed SRE provider has skilled SRE staff who already know how to assess and instrument modern software for typical performance and reliability tracking, saving you time and money in discovering these things in your business. Instead, with a managed SRE service, you get to focus on defining Key Performance Indicators (KPIs) and other reliability metrics for your business services, driving value for business stakeholders.
Take a look at Part 1 of our series for an intro to Site Reliability Engineering and how it relates to Managed Services for IT Operations.

Russ McKendrick
Practice Manager (SRE & DevOps)
Russ heads up the SRE & DevOps team here at N4Stack.
He's spent almost 25 years working in IT and related industries and currently works exclusively with Linux.
When he's not out buying way too many records, Russ loves to write and has now published six books.
To find out more about Russ click here!